







Mastering the development of a RAG (Retrieval Augmented Generation)

The rise of Generative AI, particularly large language models (LLMs), is transforming business processes by unlocking significant productivity gains for employees.
Retrieval Augmented Generation (RAG) techniques, which enable the integration of external knowledge bases into LLMs, stand out as a major innovation in this space. They help mitigate hallucinations, one of the key challenges in deploying LLMs within business applications.
RAG use cases are broad and highly promising. As a customer support tool, a RAG system can deliver accurate and contextualised responses, improving customer satisfaction and retention. In market analysis, it can synthesise complex datasets and generate valuable insights to support strategic decision making. In sales, it can act as an assistant capable of aggregating large volumes of information in real time, enhancing commercial performance.
However, building a high performing RAG system is not straightforward. It requires a rigorous approach and a deep understanding of business needs. Poorly designed implementations can result in ineffective and disappointing chatbots. With the right strategy and execution, however, RAG systems can transform internal processes and become a true strategic asset.
What is a RAG ?
A RAG is an application of large language models, such as ChatGPT, that combines two key techniques : information retrieval and text generation.
In simple terms, a RAG is a chatbot designed to search for relevant information within a large document database and use it to generate coherent, context aware responses or content. This technology is particularly valuable for organisations that need to process large volumes of data while delivering fast and accurate answers.
RAG systems offer several advantages. They can cite sources when responding, and integrate information beyond their initial training scope, including real time data or internal company knowledge. They help address some of the main limitations of LLMs, such as lack of interpretability and static knowledge bases.
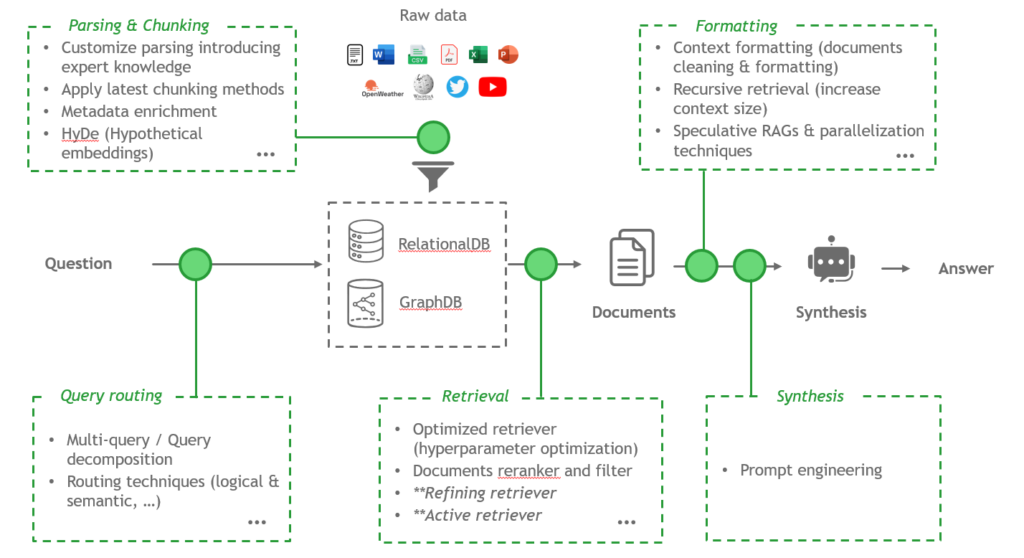
To understand how a RAG works, it is useful to break it down into three main components : the parser, the retriever and the synthesis layer.
- The parser : this component is responsible for extracting information from both structured data sources, such as tables, and unstructured data, including slides and PDFs. This foundational layer enables the extraction and structuring of information that will later be provided to the chatbot.
- The retriever : this component is responsible for identifying relevant information within a database or a collection of documents. It retrieves text segments, chunks, or full documents that are most likely to answer the user’s query.
- The synthesis layer : the final component is the generation or synthesis block. Once the relevant documents have been retrieved, a language model generates a coherent and contextualised response based on the information provided.
None of these components should be overlooked, as weaknesses in any of them can significantly degrade the overall performance of the RAG system.
Optimising a RAG
To optimise a RAG, each of its components can be improved individually, as each presents its own set of parameters and challenges.
- The parser : the main difficulty lies in interpreting complex documents, such as PDFs with graphical or visual elements. To address this, it is possible to leverage OCR (Optical Character Recognition) models or multimodal language models such as GPT Vision. However, there is a trade off between cost, performance and hallucination risk, as language models may introduce inaccuracies.
Another key aspect of the parser is data enrichment through metadata. For example, adding context, formatting or domain specific knowledge can significantly enhance the quality of the extracted information. - The retriever : optimising a retriever is a balancing act. It is essential to find the right trade off between the number and size of retrieved documents, providing enough information for the LLM to generate a relevant answer without overwhelming it with excessive data.
Advanced techniques such as active or refining retrievers, or dynamic hyperparameter retrievers, allow model parameters to be adjusted based on the user query, enabling a more precise balance for each request. - The synthesis layer : this is often the most complex component to optimise. The success of the synthesis stage largely depends on prompt engineering, meaning the way instructions are formulated and provided to the LLM.
Prompts must follow specific structures to fully leverage the capabilities of advanced language models. It is possible to guide reasoning through techniques such as step by step reasoning, including Chain of Thought or Tree of Thought approaches.
A wide range of techniques exists, and having a robust evaluation framework is essential to quickly test and compare different prompts.
Key success factors for a RAG
The success of a RAG relies on a well designed architecture and strong expertise in generative AI. It is essential to focus on several key aspects :
- A unique and tailored solution : there is no one size fits all RAG architecture. Even more importantly, advanced techniques mentioned earlier can deliver excellent performance in certain contexts, while significantly degrading performance in others. It is therefore critical to thoroughly test different architectures to maximise the chances of building a high performing solution
- A scalable architecture : many technological building blocks exist, but they differ in terms of performance, cost and scalability. The architecture must be tailored to the specific use case to best meet business needs
- User support and adoption : while tool performance is important, user engagement is even more critical. End users should be involved in co building the solution, bringing their perspective into the project. These tools can be complex to adopt and require a period of onboarding and training to ensure maximum adoption
Conclusion
While building a RAG can generate significant value across many business functions, it requires deep expertise to avoid common pitfalls and ensure both performance and adoption.
Eleven leverages strong experience and expertise in these technologies to support clients end to end in their transformation driven by generative AI, helping them fully unlock the potential of RAG.
To learn more about how we can help you integrate a RAG into your organisation, feel free to contact Simon Georges-Kot, Principal at eleven strategy.


