







Maîtriser le développement d'un RAG (Retrieval Augmented Generation)

L'essor de l'IA générative, en particulier les grands modèles linguistiques (LLM), transforme les processus métier en offrant des gains de productivité significatifs aux employés.
Les techniques de Génération Augmentée par Récupération (RAG), qui permettent l'intégration de bases de connaissances externes dans les LLM, s'imposent comme une innovation majeure dans ce domaine. Elles contribuent à atténuer les hallucinations, l'un des défis majeurs du déploiement des LLM dans les applications d'entreprise.
Les cas d'usage du RAG sont vastes et très prometteurs. En tant qu'outil de support client, un système RAG peut fournir des réponses précises et contextualisées, améliorant ainsi la satisfaction et la fidélisation des clients. Dans l'analyse de marché, il peut synthétiser des ensembles de données complexes et générer des informations précieuses pour éclairer la prise de décision stratégique. Dans les ventes, il peut agir comme un assistant capable d'agréger de grands volumes d'informations en temps réel, améliorant ainsi la performance commerciale.
Cependant, la construction d'un système RAG performant n'est pas simple. Elle exige une approche rigoureuse et une compréhension approfondie des besoins métier. Des implémentations mal conçues peuvent aboutir à des chatbots inefficaces et décevants. Avec la bonne stratégie et une exécution adéquate, les systèmes RAG peuvent transformer les processus internes et devenir un véritable atout stratégique.
Qu'est-ce qu'un RAG ?
Un RAG est une application des grands modèles linguistiques, tels que ChatGPT, qui combine deux techniques clés : la récupération d'informations et la génération de texte.
En termes simples, un RAG est un chatbot conçu pour rechercher des informations pertinentes au sein d'une vaste base de données documentaires et les utiliser pour générer des réponses ou du contenu cohérents et contextuels. Cette technologie est particulièrement précieuse pour les organisations qui doivent traiter de grands volumes de données tout en fournissant des réponses rapides et précises.
Les systèmes RAG offrent plusieurs avantages. Ils peuvent citer leurs sources lors des réponses et intégrer des informations allant au-delà de leur portée de formation initiale, y compris des données en temps réel ou des connaissances internes à l'entreprise. Ils contribuent à pallier certaines des principales limitations des LLM, telles que le manque d'interprétabilité et les bases de connaissances statiques.
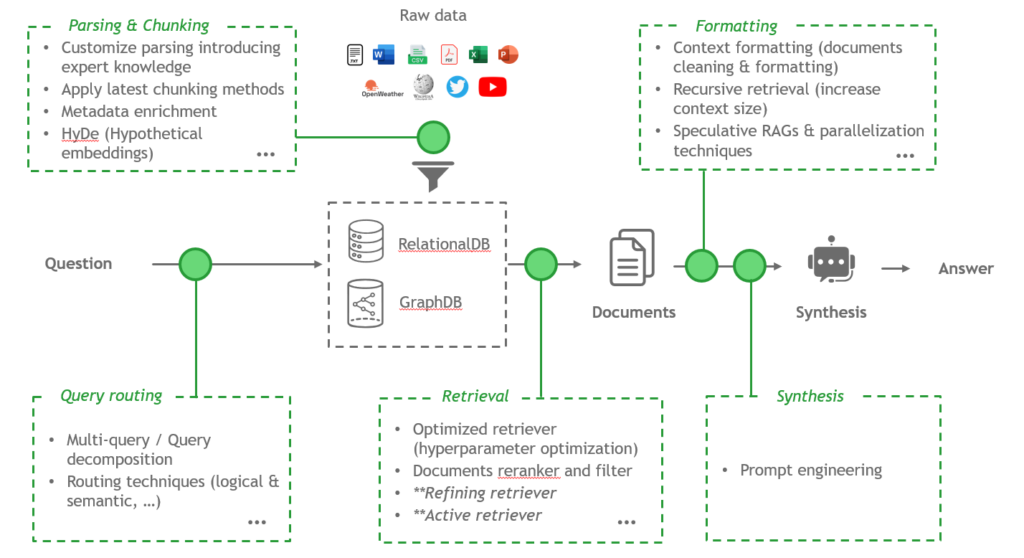
Pour comprendre le fonctionnement d'un RAG, il est utile de le décomposer en trois composants principaux : le parseur, le récupérateur et la couche de synthèse.
- Le parseur : ce composant est chargé d'extraire des informations à partir de sources de données structurées, telles que des tableaux, et de données non structurées, y compris des diapositives et des PDF. Cette couche fondamentale permet l'extraction et la structuration des informations qui seront ensuite fournies au chatbot.
- Le récupérateur : ce composant est chargé d'identifier les informations pertinentes au sein d'une base de données ou d'une collection de documents. Il récupère des segments de texte, des blocs ou des documents entiers qui sont les plus susceptibles de répondre à la requête de l'utilisateur.
- La couche de synthèse : le dernier composant est le bloc de génération ou de synthèse. Une fois les documents pertinents récupérés, un modèle linguistique génère une réponse cohérente et contextualisée basée sur les informations fournies.
Aucun de ces composants ne doit être négligé, car des faiblesses dans l'un d'entre eux peuvent dégrader considérablement la performance globale du système RAG.
Optimiser un RAG
Pour optimiser un RAG, chacun de ses composants peut être amélioré individuellement, car chacun présente son propre ensemble de paramètres et de défis.
- Le parseur : la principale difficulté réside dans l'interprétation de documents complexes, tels que les PDF avec des éléments graphiques ou visuels. Pour y remédier, il est possible de tirer parti des modèles d'OCR (Optical Character Recognition) ou des modèles de langage multimodaux tels que GPT Vision. Cependant, il existe un compromis entre le coût, la performance et le risque d'hallucination, car les modèles de langage peuvent introduire des inexactitudes.
Un autre aspect clé du parseur est l'enrichissement des données via les métadonnées. Par exemple, l'ajout de contexte, de formatage ou de connaissances spécifiques au domaine peut améliorer considérablement la qualité des informations extraites. - Le récupérateur : l'optimisation d'un récupérateur est un exercice d'équilibre. Il est essentiel de trouver le juste équilibre entre le nombre et la taille des documents récupérés, en fournissant suffisamment d'informations au LLM pour générer une réponse pertinente sans le submerger de données excessives.
Des techniques avancées telles que les récupérateurs actifs ou de raffinement, ou les récupérateurs à hyperparamètres dynamiques, permettent d'ajuster les paramètres du modèle en fonction de la requête de l'utilisateur, permettant un équilibre plus précis pour chaque demande. - La couche de synthèse : c'est souvent le composant le plus complexe à optimiser. Le succès de l'étape de synthèse dépend en grande partie de l'ingénierie des prompts, c'est-à-dire la manière dont les instructions sont formulées et fournies au LLM.
Les prompts doivent suivre des structures spécifiques pour exploiter pleinement les capacités des modèles de langage avancés. Il est possible de guider le raisonnement à travers des techniques telles que le raisonnement étape par étape, y compris les approches Chain of Thought ou Tree of Thought.
Une large gamme de techniques existe, et disposer d'un cadre d'évaluation robuste est essentiel pour tester et comparer rapidement différents prompts.
Facteurs clés de succès pour un RAG
Le succès d'un RAG repose sur une architecture bien conçue et une solide expertise en IA générative. Il est essentiel de se concentrer sur plusieurs aspects clés :
- Une solution unique et sur mesure : il n'existe pas d'architecture RAG universelle. Plus important encore, les techniques avancées mentionnées précédemment peuvent offrir d'excellentes performances dans certains contextes, tout en dégradant considérablement les performances dans d'autres. Il est donc crucial de tester minutieusement différentes architectures pour maximiser les chances de construire une solution performante.
- Une architecture évolutive : de nombreuses briques technologiques existent, mais elles diffèrent en termes de performance, de coût et d'évolutivité. L'architecture doit être adaptée au cas d'usage spécifique pour répondre au mieux aux besoins métier.
- Support utilisateur et adoption : si la performance de l'outil est importante, l'engagement des utilisateurs est encore plus critique. Les utilisateurs finaux doivent être impliqués dans la co-construction de la solution, apportant leur perspective au projet. Ces outils peuvent être complexes à adopter et nécessitent une période d'intégration et de formation pour assurer une adoption maximale.
Conclusion
Bien que la construction d'un RAG puisse générer une valeur significative dans de nombreuses fonctions métier, elle nécessite une expertise approfondie pour éviter les pièges courants et garantir à la fois la performance et l'adoption.
Eleven s'appuie sur une solide expérience et expertise dans ces technologies pour accompagner les clients de bout en bout dans leur transformation portée par l'IA générative, les aidant à libérer pleinement le potentiel du RAG.
Pour en savoir plus sur la manière dont nous pouvons vous aider à intégrer un RAG dans votre organisation, n'hésitez pas à contacter Simon Georges-Kot, Principal chez eleven strategy.


