







ChatGPT : une technologie prometteuse, si l'on sait l'utiliser à bon escient
Après le « NFT » en 2020/21, le « métavers » en 2021/22, « ChatGPT » pourrait sans aucun doute être considéré comme le « mot-clé de l'année 2022/23 ». Acclamé ou décrié, il est vivement débattu à la télévision, sur les réseaux sociaux et au sein des entreprises. S'agit-il de l'émergence d'une technologie révolutionnaire, au même titre que l'avènement des microprocesseurs, comme le souligne Bill Gates, ou simplement de « la popularisation d'une technologie déjà existante », comme l'affirme Yann LeCun, directeur scientifique de l'IA chez Facebook ?
La réponse se situe probablement entre les deux. Oui, ChatGPT apporte de nombreuses avancées en matière de traitement du langage humain. Utilisé habilement, il peut améliorer significativement les performances de certains modèles d'IA, auparavant à la pointe de la technologie. Mais derrière ChatGPT se cachent des modèles de langage connus depuis plusieurs années, déjà largement utilisés et exploités par les experts en IA, notamment chez eleven, où ils ont été mis en œuvre pour plus d'une douzaine de projets pour des acteurs industriels et des start-ups.
I- Comment ça marche en bref
ChatGPT, le chatbot développé par OpenAI, est une application d'une technologie en plein essor depuis 2018 : les LLM, ou Modèles d'apprentissage du langage. Parfois également appelés « modèles fondamentaux », ils sont le cœur de la compréhension du langage humain par les machines. Pour ce faire, ils s'appuient sur une architecture complexe de réseaux neuronaux et des centaines de milliards de paramètres à ajuster de manière itérative. Le principe est simple : pour une phrase d'exemple donnée, prédire le mot suivant.
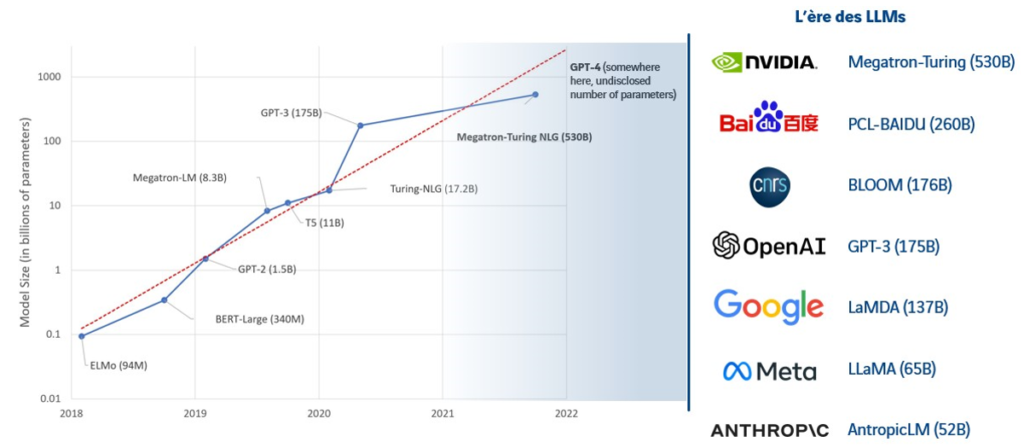
L'IA détermine ainsi le sens d'un mot en tenant compte des contextes dans lesquels elle l'a rencontré. L'entraînement d'un modèle avec autant de paramètres nécessite une grande quantité de données, généralement issues de données accessibles au public telles que Wikipédia (3 % du corpus d'entraînement), des articles de presse, des livres en libre accès, etc. À titre d'exemple, GPT-3 (Generative Pre-trained Transformers-3), composé de 175 milliards de paramètres, a nécessité l'ingestion de près de 570 Go de données, soit environ 300 milliards de mots. Ces chiffres pharaoniques sont synonymes de coûts financiers considérables : on parle de 4,6 millions de dollars dépensés pour l'entraînement de GPT-3, sans parler de l'impact écologique qui en découle.
Figure 1 : Évolution du nombre de paramètres utilisés par les modèles LLM depuis 2018 (4).
Il en résulte des modèles d'IA très puissants, capables de comprendre toute la sémantique de chaque langue sur laquelle ils ont été entraînés, leur permettant de réaliser de nombreux cas d'usage : traduction de texte, rédaction d'essais, etc. Plus largement, ils peuvent être spécialisés, c'est-à-dire adaptés à un cas d'usage, leur offrant un large éventail de tâches possibles, à l'image de ChatGPT.
De GPT à ChatGPT
ChatGPT est un chatbot basé sur GPT-3 capable d'émuler l'expérience humaine d'une conversation réelle. Treize mille paires de questions/réponses ont été utilisées pour transformer un modèle de « prédiction du mot suivant » en un modèle capable de répondre à des questions. En parallèle, un modèle de récompense – l'apprentissage par renforcement – aide ChatGPT à s'orienter vers la production de réponses attendues par un humain. Cette dernière étape, au cours de laquelle des humains classent différentes réponses possibles à la même question, permet la modération de certains contenus considérés comme illégaux ou dangereux.
II- Une technologie loin d'être infaillible
Malgré ses performances remarquables, ChatGPT souffre à ce jour de sévères limitations éthiques et techniques.
Limitations éthiques
D'un point de vue éthique, la technologie est confrontée à un certain nombre de problèmes importants, liés à son fonctionnement et à son processus d'entraînement.
- Confidentialité : la version gratuite de ChatGPT peut stocker et réutiliser toute saisie de texte de l'utilisateur, ce qui soulève d'importantes questions de confidentialité.
- Propriété intellectuelle : le droit d'auteur du contenu généré par l'IA constitue actuellement un vide juridique. Généralement, les modèles comme ChatGPT sont entraînés sur des contenus divers, tels que de la musique, des images et des livres, sans offrir de compensation aux créateurs originaux. Cette approche pourrait entraîner des conflits juridiques potentiels et des défis concernant les droits de propriété intellectuelle.
- Biais et stéréotypes : ChatGPT peut apprendre des préjugés ou des biais raciaux, de classe ou autres, et donner des réponses erronées en raison d'un manque d'équité et d'inclusivité dans le processus d'entraînement du modèle.
- Contenu nuisible : bien que des mesures soient en place pour empêcher ChatGPT de générer du contenu nuisible, contourner ces protections semble relativement facile. Par exemple, le simple fait de situer l'interaction dans le cadre d'un roman policier peut permettre au modèle de générer du contenu qui ne serait pas censuré.
Les LLM basés sur des données ouvertes et disponibles en open source, tels qu'Alpaca, développé par Stanford, se heurtent aux limites de la confidentialité et de la propriété intellectuelle, mais sont moins performants et restent sujets aux biais et aux contenus préjudiciables.
Limitations techniques
ChatGPT fournit une réponse plausible, ce qui est le moins qu'on puisse dire, étant donné tous les contextes qu'il a rencontrés lors de son entraînement. Il est donc étranger au concept de vérité. De ce point clé découlent plusieurs limitations techniques :
- Informations erronées : ChatGPT, comme tout modèle d'IA, peut occasionnellement générer des informations incorrectes (effet d'« hallucination »). Une étude de l'Université de Hong Kong a mesuré un taux d'erreur de 37 % (3). Sur des sujets controversés, il peut commettre des erreurs en fournissant des réponses guidées par le consensus plutôt que par un point de vue équilibré.
- Évolution limitée : l'IA générative comme ChatGPT est le reflet des données sur lesquelles elle a été entraînée. Elle fonctionne de manière optimale si les sources de données sont de bonne qualité et convergentes.
- Compréhension limitée : malgré ses capacités avancées, ChatGPT n'est pas conçu pour comprendre fondamentalement les tâches qu'il exécute. Il lui manque la capacité de raisonnement logique, pour résoudre des problèmes mathématiques par exemple, ce qui nécessite le développement d'outils dédiés.
- Outil de persuasion : ChatGPT n'est pas conçu pour vérifier ses données, mais pour générer des réponses probables basées sur des contextes. Dès lors, il est rapidement possible de tromper ChatGPT, en le persuadant de fausses informations, qu'il pourra ensuite utiliser comme source d'information.
Plusieurs options existent pour contourner ces limitations techniques : utiliser des frameworks pour sourcer l'information et rechercher des sources externes (comme LangChain), utiliser GPT-4 (la version payante la plus récente et plus puissante d'OpenAI), ou spécialiser ChatGPT à des cas d'usage spécifiques.
III- Comment exploiter tout le potentiel de ChatGPT
Heureusement, il ne s'agit pas principalement d'entraîner un modèle linguistique à partir de zéro, mais de tirer parti de son apprentissage linguistique pour lui faire effectuer des tâches spécifiques. C'est ce qu'on appelle le « Transfer Learning », lorsqu'un modèle pré-entraîné est ajusté à un cas d'usage spécifique, une étape qui est significativement moins énergivore.
ChatGPT est une technologie utile et prometteuse, qui pourrait être utilisée dans de nombreux domaines à l'avenir. Chez eleven, nous constatons un intérêt de la part de différentes professions qui correspond à la couverture médiatique du sujet, et nous leur parlons de nombreuses applications :
- Communication : génération de contenu avec du texte, des images et des vidéos pour les supports de communication ou les réseaux sociaux
- Marketing : génération de contenu pour personnaliser les offres
- Achats et ventes : analyse automatique des appels d'offres
- Ventes : aide à la réponse aux questions, devis, appels d'offres
- Service client : agents conversationnels, analyse des retours clients,...
- Ressources humaines : tri automatique des CV avec extraction des informations clés, génération de fiches de poste, élaboration de questionnaires pour l'intégration des nouveaux collaborateurs,...
- Juridique : analyse de documents pour identifier la présence de données personnelles, analyse et synthèse de contrats, génération de modèles de contrats,...
- Formation : génération de contenu, scénarios pour supports de formation
- Veille technologique : synthèse de contenu en ligne, livres blancs,...
Plus généralement, les modèles de langage peuvent être mis à profit pour de nombreuses tâches, de l'automatisation des processus aux tâches humaines complexes, telles que l'analyse de données et le traitement de documents.
Les projets qu'eleven a accompagnés ont cependant mis en évidence certains prérequis pour une utilisation efficace de la technologie :
- Le Plug & Play ne fonctionne pas : l'étape d'adaptation du modèle est essentielle pour obtenir de bonnes performances sur des données spécifiques, comme les documents techniques d'une entreprise de construction, ou la compréhension d'un plan local de développement pour en extraire les informations attendues.
- La rédaction des prompts est centrale pour obtenir une réponse attendue : ils doivent être à la fois clairs, concis et inclure suffisamment de contexte pour être représentatifs des réponses que le modèle est censé générer.
- Le corpus de documents doit être large et varié : la sélection des documents pour le fine-tuning est un facteur clé à prendre en compte, et doit englober les différents sujets pour aider le modèle à apprendre un ensemble diversifié de réponses sans s'éloigner de l'objectif initial de l'outil en question.
En suivant ces préconisations, nous avons amélioré la performance d'extraction d'informations clés du plan local de développement de 13% avec une méthode Plug & Play, à 55% avec une bonne présélection du corpus et de l'ingénierie de prompts. À noter que la meilleure performance obtenue sans modèles de langage est de 26% pour un tel sujet, soit deux fois mieux que GPT sans ajustements, et deux fois moins bien que GPT avec accompagnement.
Eleven accompagne les entreprises dans l'expérimentation, le développement et l'intégration de ces outils pour des cas d'usage concrets. Avec une approche stratégique, des attentes réalistes, et surtout une compréhension claire de son fonctionnement et de ses limites, les entreprises peuvent réellement tirer parti de la technologie derrière ChatGPT.
Sources :
(1) https://www.independent.co.uk/tech/harvard-chatbot-teacher-computer-science-b2363114.html
(2) https://fr.wikipedia.org/wiki/GPT-3
(3) https://arxiv.org/pdf/2302.04023.pdf
(4) https://huggingface.co/blog/large-language-models


